
前言:
我们使用瓦力机器人的形象仅为技术分享与演示,无任何商业目的。
本篇教程主要介绍瓦力机器人通过树莓派接入deepseek实现对话的全过程,本项目附有镜像文件、接线图,有兴趣的伙伴自取。
接入deepseek的瓦力可以“思考”实现自由对话,但整体反馈速度较慢需要8秒左右,目前我们还没接入动作和联网思考。
本篇希望能给对瓦力AI对话感兴趣的伙伴提供思路,想继续升级的朋友可以自行尝试,期待各位不同的瓦力!
具体实现效果可参考我们发布的视频:
需要准备的硬件
关于瓦力机器人如何如何组装、3D打印文件、arduino舵机校准等具体操作请移步上篇。
从零开始制作的材料清单请参考:
接入deepseek的方案用到的主控硬件是树莓派,还需要一对喇叭和一个麦克风。
-
树莓派4代B型*1个,规格:4代B型,单主板内存RAM:8GB
-
喇叭和麦克风找相似的就可以


上篇篇中接入的语音模块硬件套组可以移除:
这些不需要使用:
ASR-PRO语音智能语音识别控制模块*1个,规格:ASR-PRO喇叭
ASR-PRO语音智能语音识别控制模块*1个,规格:STC-LINK官方下载器(核心板专用)不带壳+4P杜邦线
ASR-PRO语音智能语音识别控制模块*1个,规格:ASR-PRO核心板4M(排针未焊)
ASR-PRO语音智能语音识别控制模块*1个,规格:高灵敏度麦克风 带咪套(核心板专用)
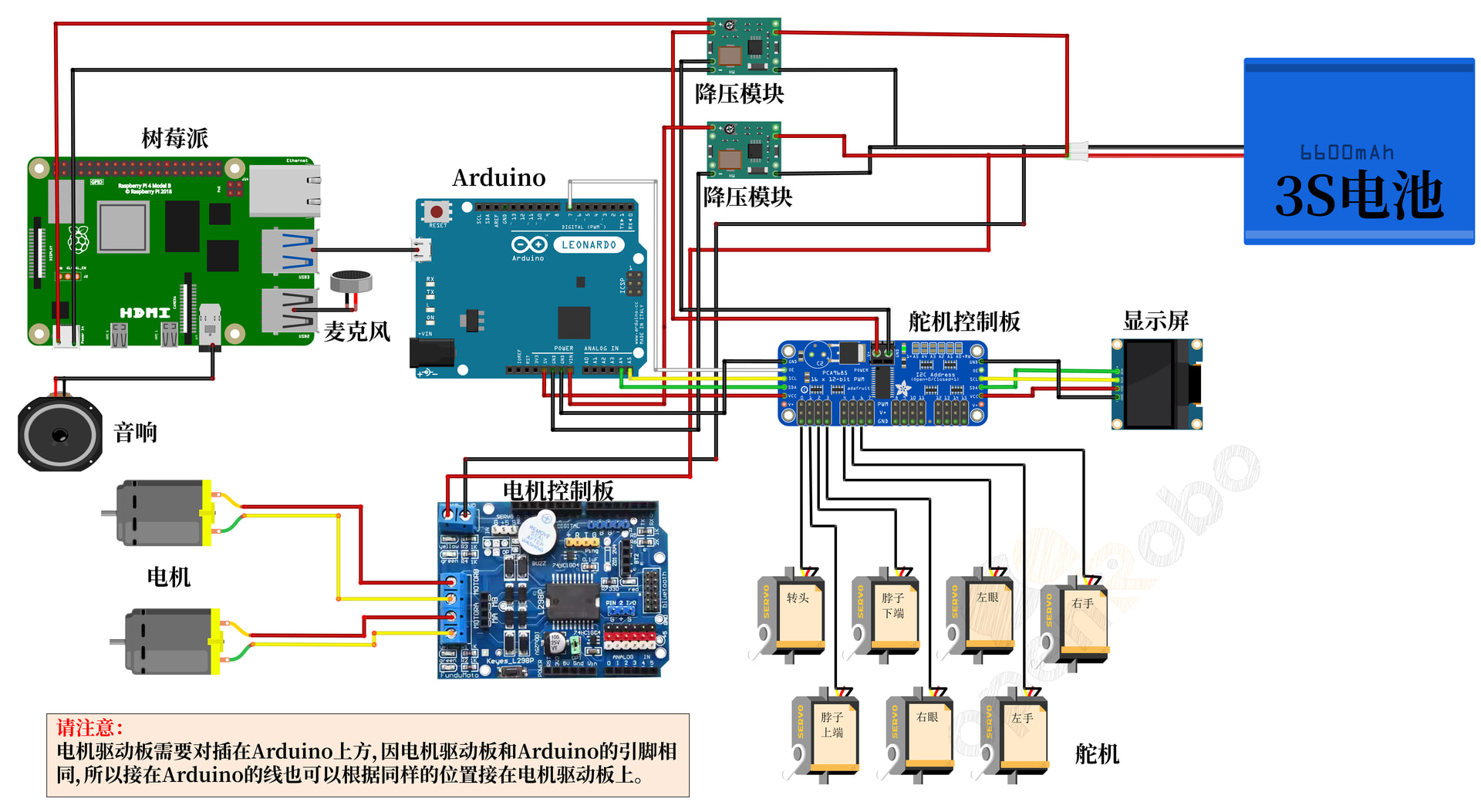
接线图
(需要高清PDF版请留言)
实现思路
以下介绍我们的整体实现思路和操作,感兴趣的可以试一下。
要让瓦力机器人装上deepseek的“大脑”实现对话效果,基础的思路是这样的:
瓦力需要被唤醒词唤醒——接着瓦力需要实时语音识别——把识别到的内容发送到deepseek进行思考——把思考的结果通过语音播放出来。
文件资料
这是我们整理好的文件包,可以先下载。
点击跳转:瓦力接入deepseek文件
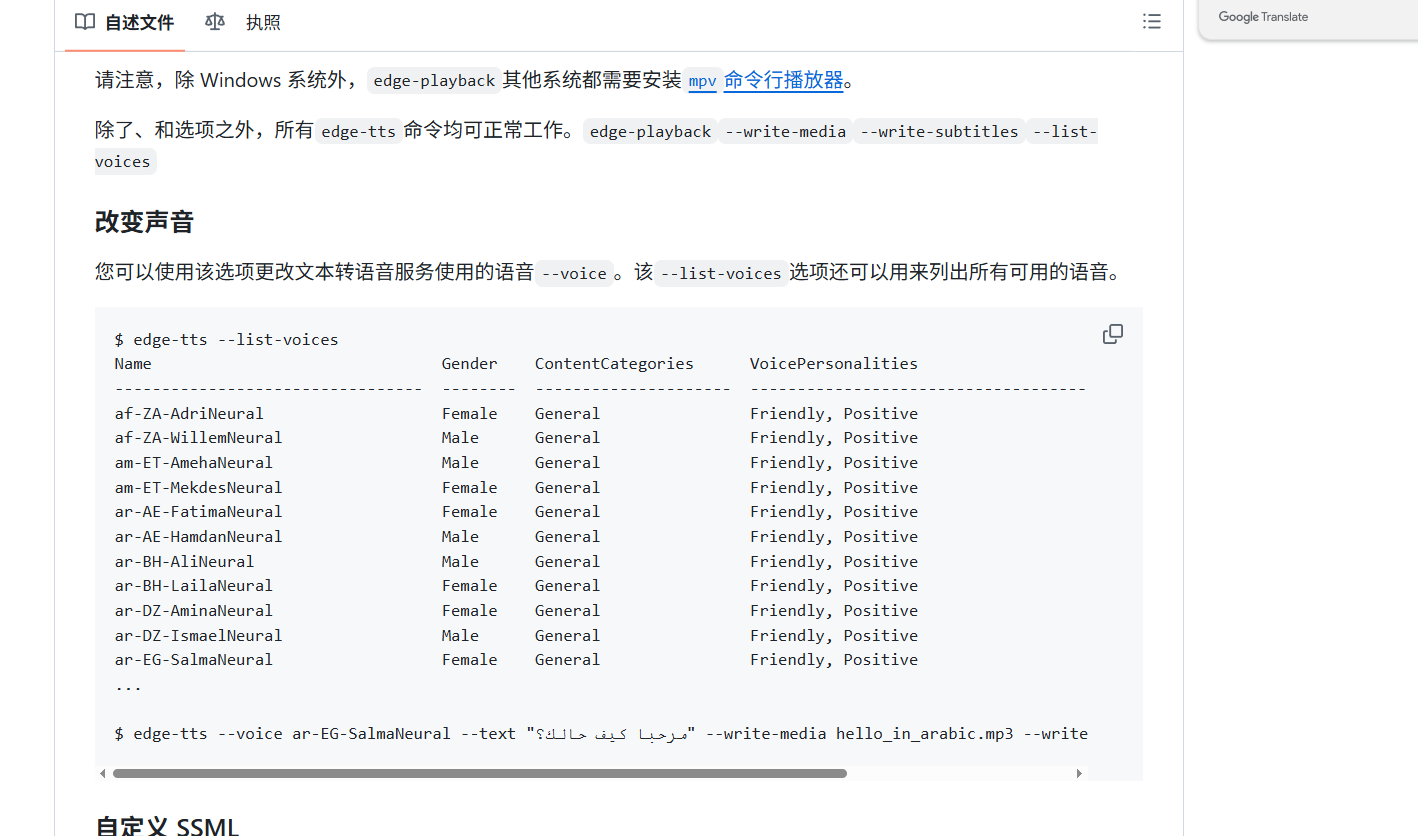
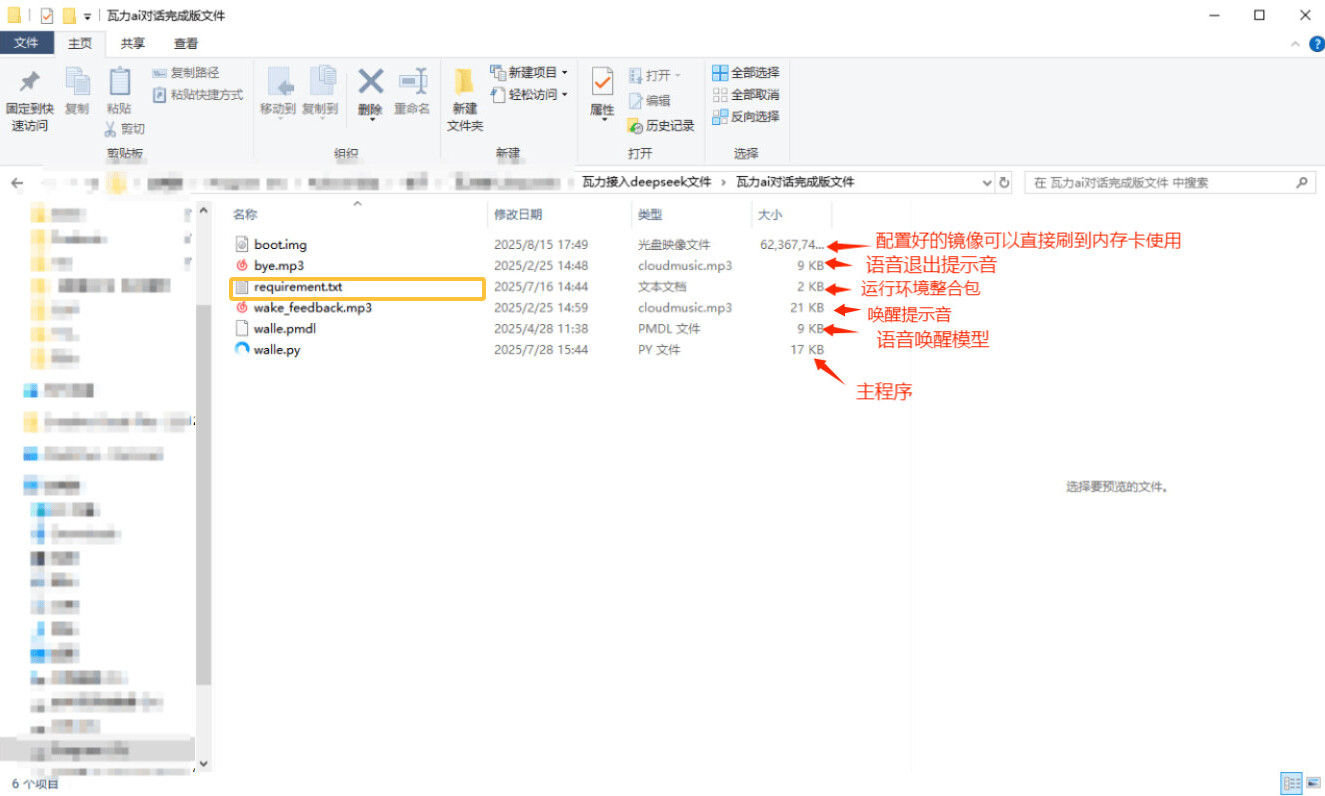
文件说明:
boot.img 配置好的镜像文件可以直接刷到内存卡使用
bye.mp3 语音退出提示音
requirement.txt 运行环境整合包
wake_feedback.mp3 唤醒提示音
walle.pmdl 语音唤醒模型
walle.py 主程序树莓派镜像文件
其中文件“boot.img” 是树莓派镜像文件已经安装好运行环境和所需文件,烧录到树莓派内存卡内,打开主程序可直接运行。
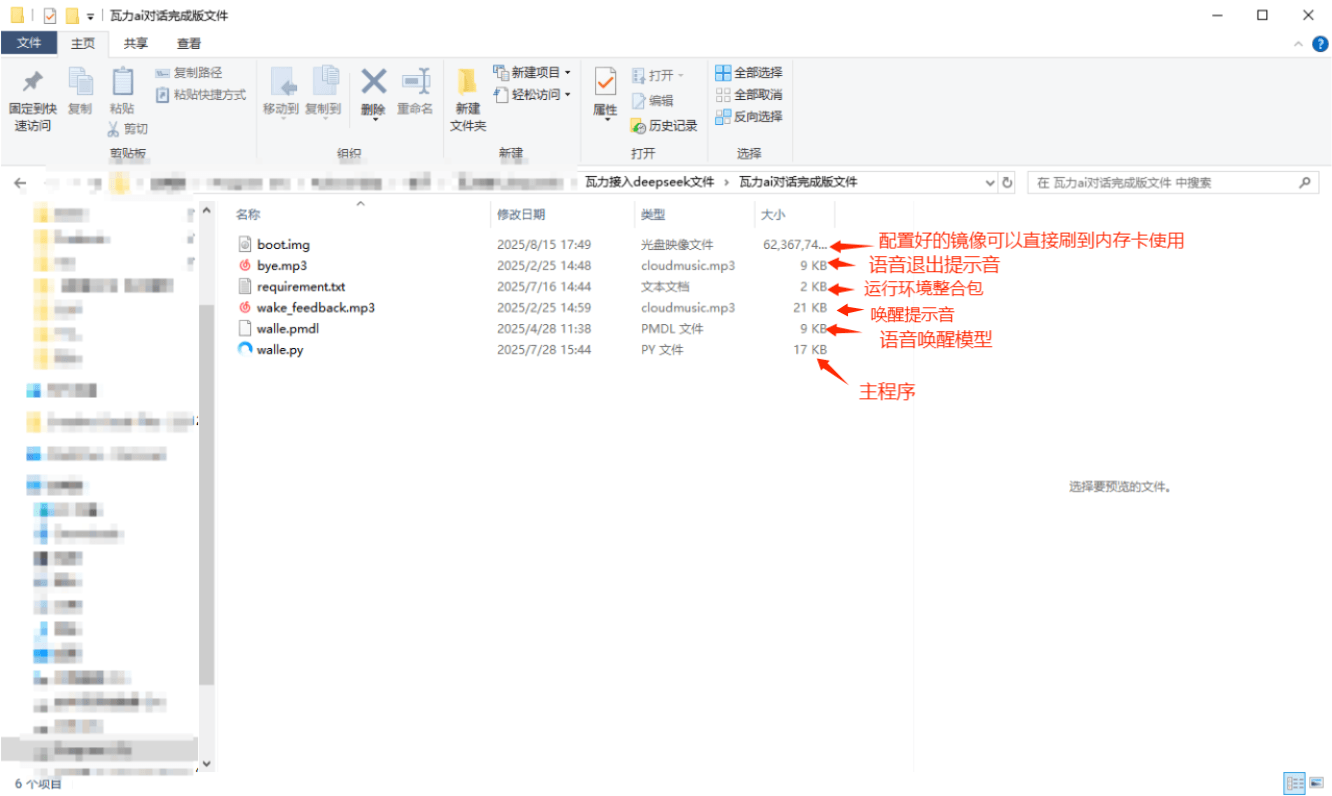
注意:提示音和退出音效可以换成自己喜欢的,但是文件名必须一致
具体操作
1.唤醒词模型
可以直接使用文件里的做唤醒词模型,我们设置的唤醒词是“瓦力瓦力”和“你好瓦力”。
也可以按照以下方法重新设置唤醒词或是自行更换唤醒词模型。
我们用的是开源的语音唤醒引擎snowboy。
Snowboy Personal Wake Word地址:https://snowboy.hahack.com/
直接用它网页上现成的工具就能训练自定义的唤醒词模型,点击录音,把想要的唤醒词录进去。
例如:我们设置的唤醒词是“瓦力瓦力”和“你好瓦力”。
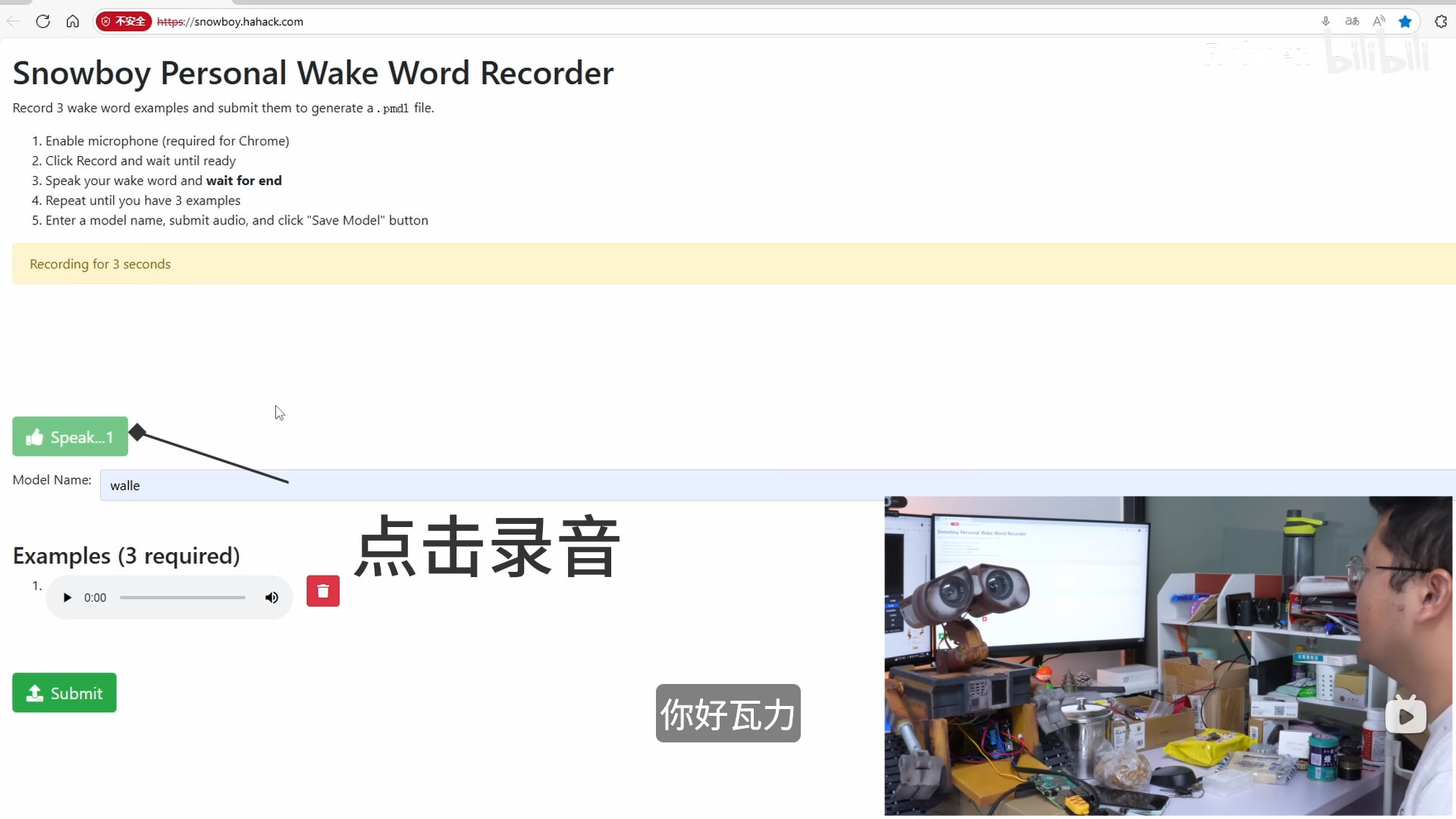
最后生成文件就是瓦力的唤醒词模型了。
也可以直接使用我提供的“walle.pmdl”文件。
2.智能语音识别
语音识别用的是阿里云的智能语音交互。
这一步需要在阿里云创建属于自己的 AppKey
参考网址和资料:
先去阿里云控制台按照上面的步骤创建一个AccessKey,如果不涉及商业可以选择免费版先试用。
根据这个操作步骤创建:获取AccessKey-阿里云帮助中心
然后登录控制台智能语音交互控制台—新建项目—项目类型选“仅语音识别”。
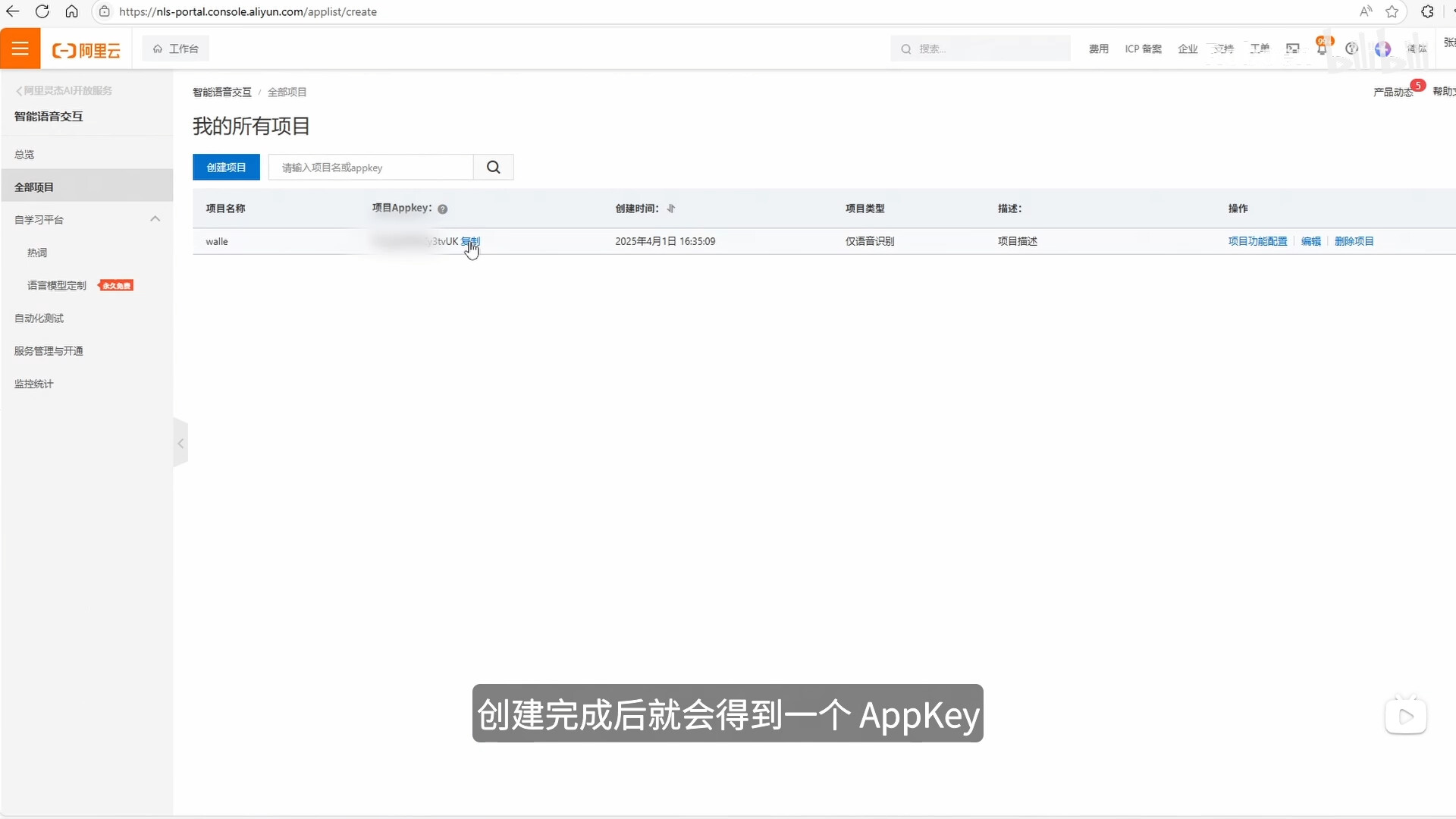
创建完成后就会得到一个 AppKey,这个Appkey后面需要写入主程序中。
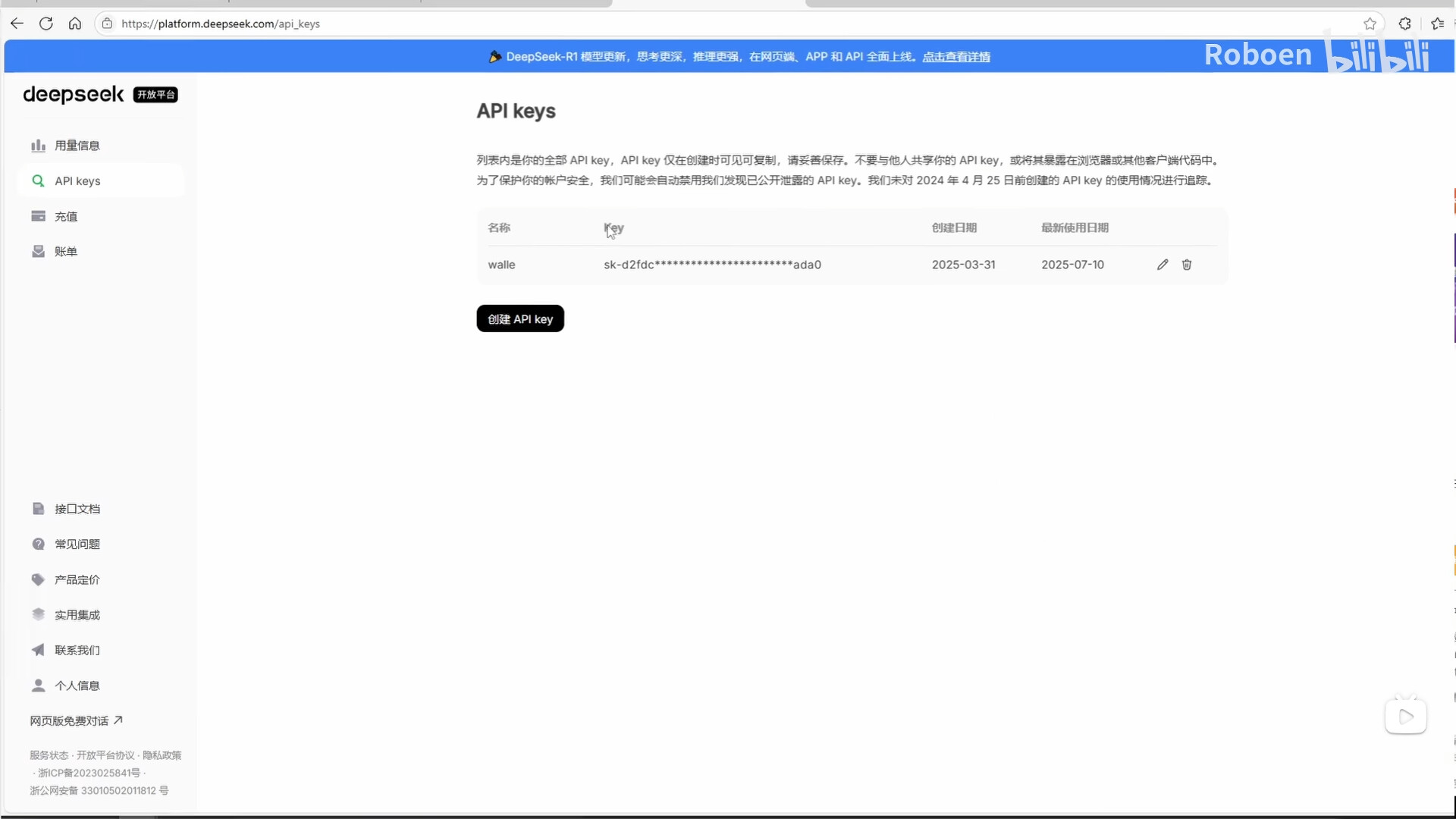
3.创建deepseek API
登录deepseek开放平台官网(https://platform.deepseek.com)
进入进入API keys页面,创建自己的API key。
瓦力主程序
主程序是我们自己写的,如果不想自己写的可以直接用我这个程序。
把刚刚2、3中得到的阿里云的APPkey和deepseek的API key替换成自己的。
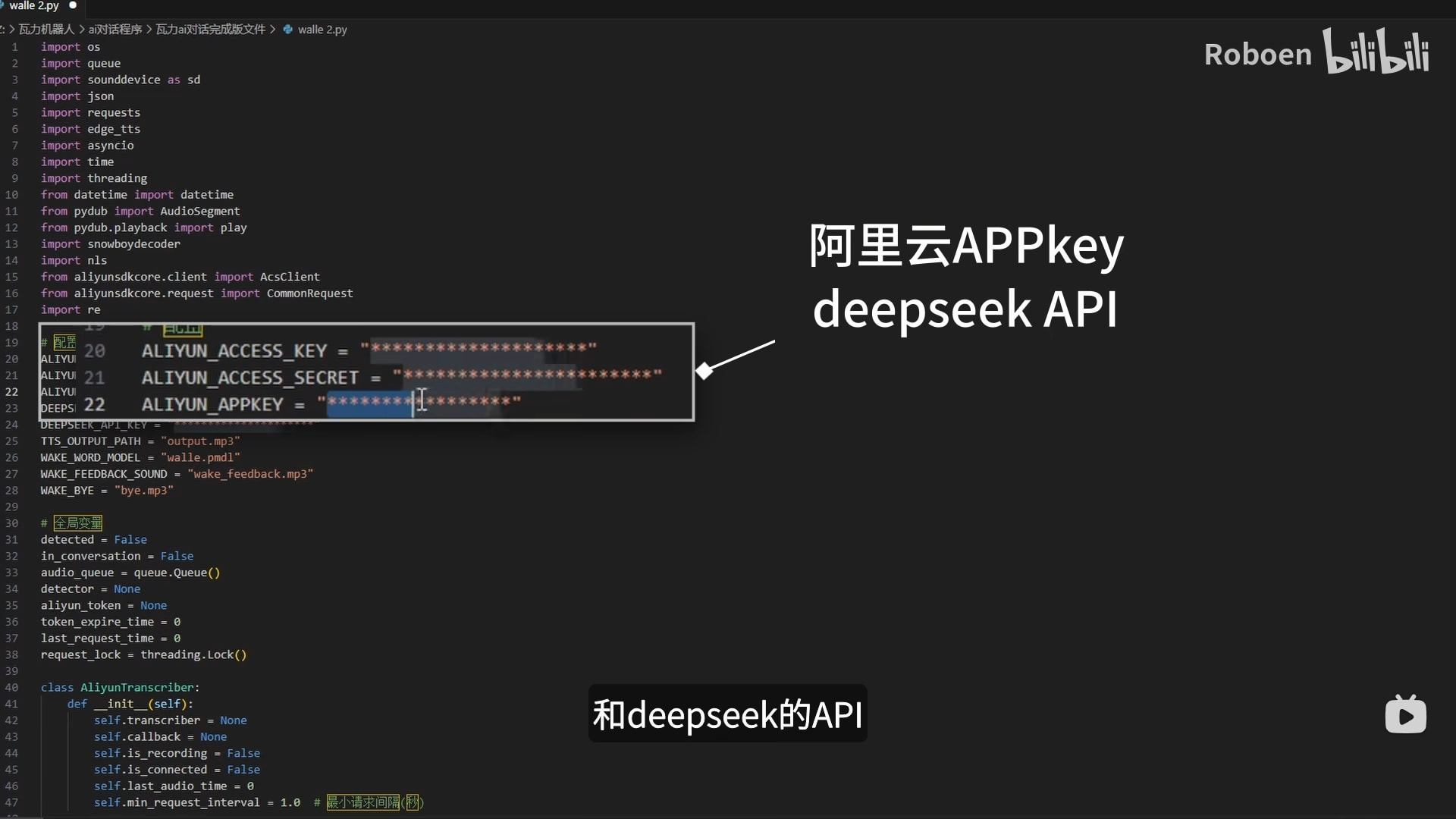
这里也可以根据需求设置角色性格,也能更换添加唤醒词和提示音。
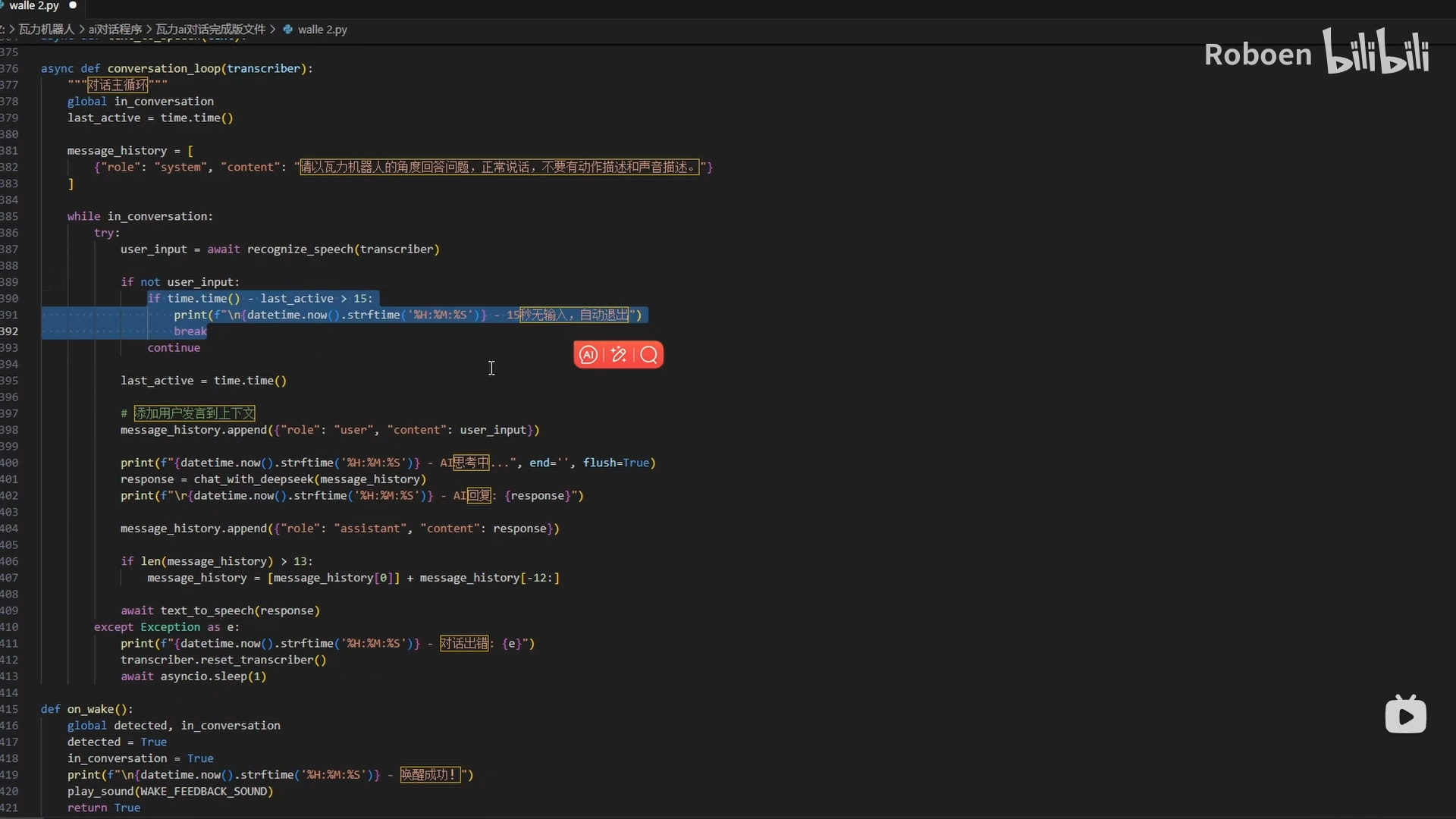
有需要的可以自己加一些设置。
例如我的程序里面就加了“15秒没有说话就自动退出,再次唤醒需要重新说唤醒词。退出时播放退出提示音。”
微软文字转语音
在主程序中安装微软的edge TTS,如果需要修改音色可以按照以下方法修改,不想改的可以不用做。
由于deepseek目前还不支持语音输出,所以这个部分我们用的是微软的 Edge TTS文字转语音功能,上面有很多不同的音色可以选择。
在Github上找到喜欢的音色对应的指令,之后在代码里输入音色指令并完成其他语音设置,这样文字转语音就可以实现了。
点击跳转:github TTS音色指令
树莓派配置
在树莓派创建一个英文文件夹,把文件夹里的文件和修改后的主程序一起拷贝到文件夹根目录。
方法一:直接使用我们给的树莓派镜像文件
这里可以直接使用我们提供的的镜像文件“boot.img ”,里面已经安装好运行环境和所需文件,把它烧录到树莓派内存卡内。
**之后打开主程序,**在终端该目录下执行“python walle.py”这个指令就可以运行主程序了。
方法二:自己配置树莓派环境
在树莓派创建一个英文文件夹,把上面提到的文件还有自己配置的Python环境包一起拷贝到文件夹根目录。
先创建一个虚拟环境命名为walle。
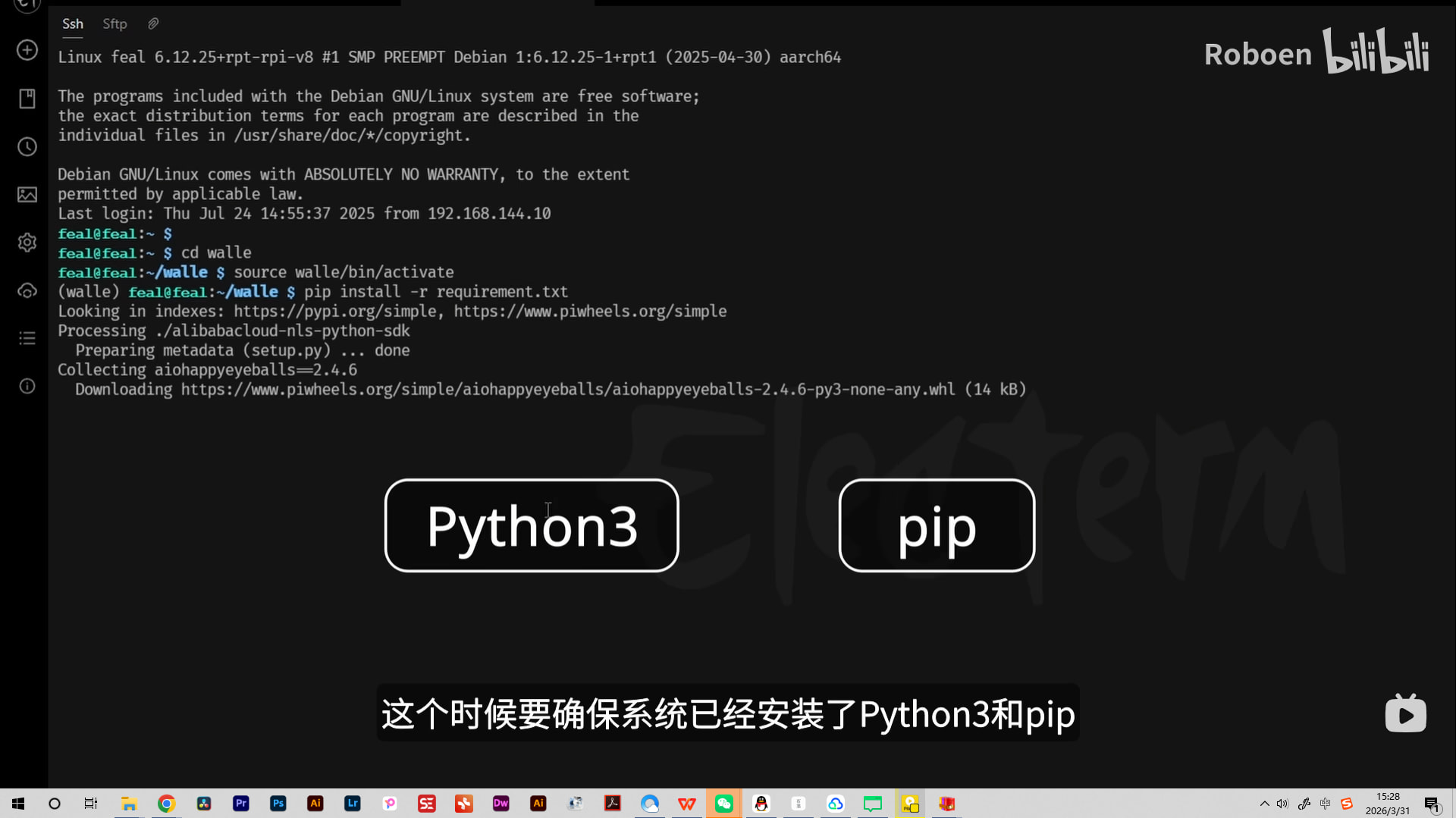
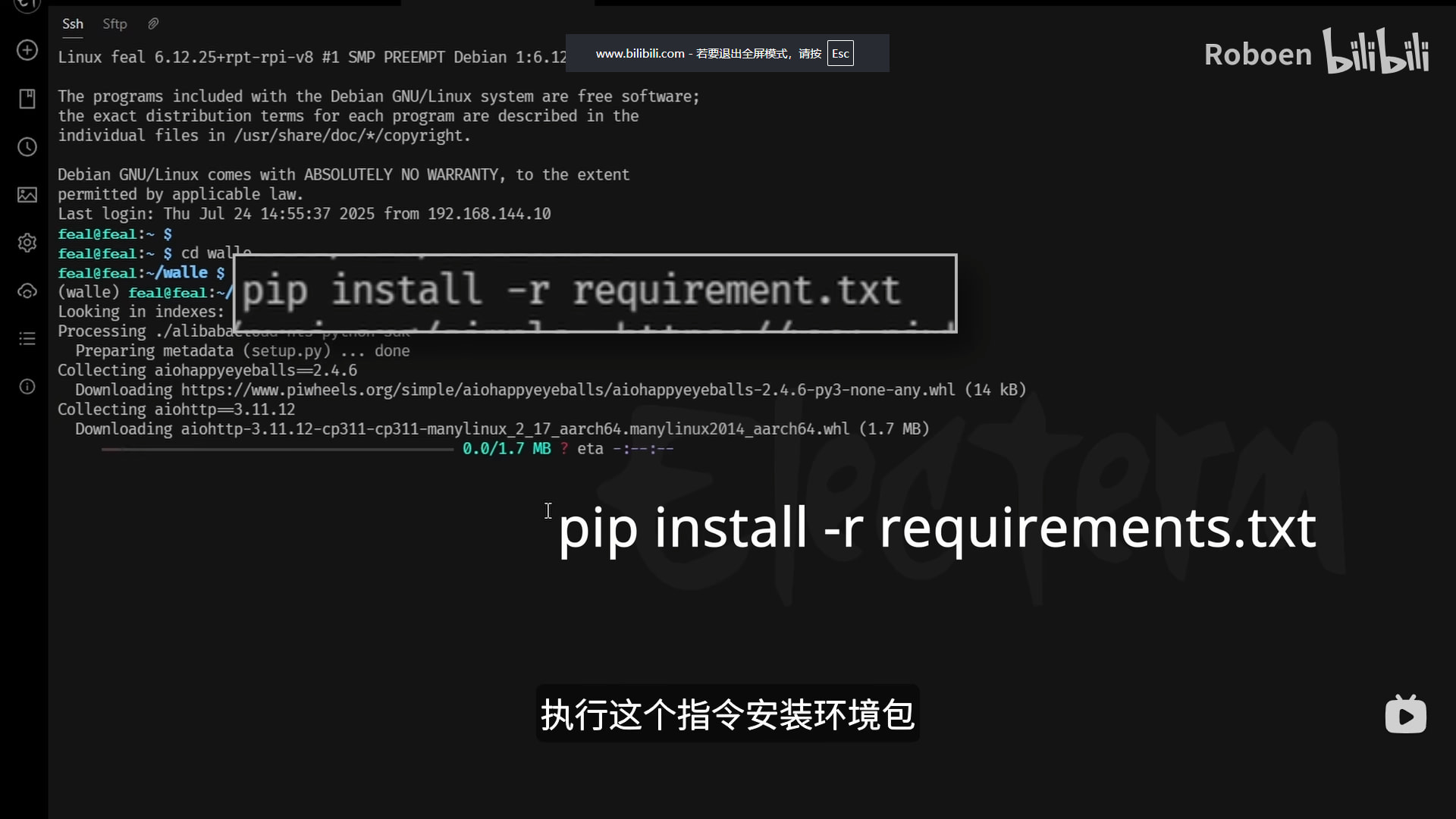
接着就是开始安装Python环境包,直接用requirement.txt这个文件进行安装。
安装前要确保系统一定要确保已经安装了Python3和pip
之后在这个文件夹目录下打开终端执行这个指令“pip install -r requirements.txt”安装环境包
一切准备好后,在终端该目录下执行“python walle.py”这个指令就可以运行主程序开始进行对话。
如果环境一直安装失败,推荐使用方法一,直接使用我们配置好的树莓派文件。
总结
以上就是瓦力接入 DeepSeek 后的整体表现。总得来说,它能顺畅聊天,而且带DeepSeek 大模型的思考,完全可以当个聊天机器人玩一玩。
但是缺点是反应速度比较慢,我们从一开始的 20 秒调到 15 秒,再到现在的 8 秒,虽然快了不少,但和专业聊天机器人比还是有点慢;
我们做的这个版本的deepseek+瓦力目前还不能进行联网搜索和动作控制,但理论上都是可以实现的,有感兴趣的朋友可以尝试看看。